
Linked Data concepts
You’re familiar with web pages. Web pages are documents written in HTML, which format content for humans to read. They’re also written with CSS, which styles the content and gives it aesthetic appeal. JavaScript is often combined to give the pages interactive functionality and to make background requests to web servers.

You’re also familiar with databases, which contain tables and columns and rows of structured data. Computers can read the data in a database, but the structure of that data is usually quite specific to the applications for which it was designed. The only systems that make good use of the data are typically only the ones which were
specifically engineered to do so. When the structure of the data has to change (as it so often does), there are
often costly downstream side-effects. Software code has to be rewritten, recompiled, and redeployed. Integrated systems may also have to be revised.
Usually, the structured data from a database ends up on a web page so that people can read it and get value out of it. But by the time the information lands on a web page, it isn’t structured anymore. It may now be easy for people to read and understand, but it isn’t easy for computers to process and understand. Computers can search for keywords in the pages, but they can’t really know, like we humans do, what the pages are about.
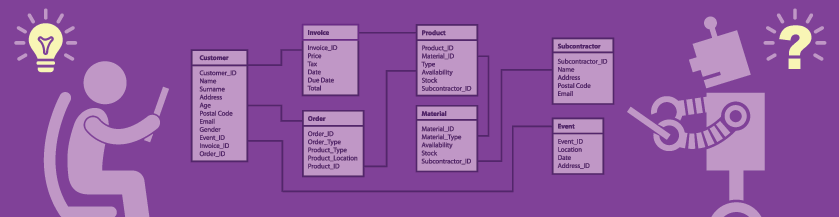
So, what we have as a result is a Web of hyperlinked documents designed for people to read. We also have a lot of databases and web services, but those are usually exposed through proprietary APIs. If we want to integrate them, we typically have a lot of custom coding to do. And even when we’ve done that custom coding, the result is still an information silo – an exclusive club reserved only for those who possess the resources to get in: people, time, and money.
There is a better way. Thanks largely in part to the efforts of the W3C a set of standards and technologies have emerged, which are turning the current web of documents into a web of data. This is giving a powerful new dimension to the existing web. You might think of it as the World Wide Database (a.k.a. the Semantic Web). On the Semantic Web, it’s much easier to integrate applications because they allow you to link data together in much the same way that we link web pages together. But perhaps more importantly, it allows for a new breed of applications that are easier for computers to interoperate with.
This is because the link in Linked Data is more powerful than a traditional hyperlink. When it relates one thing to another, it explicitly describes the nature of that relationship. By providing context to its connection, it creates knowledge. That’s right – the link itself is knowledge. And because Linked Data can connect URIs that
identify real-world things, not just documents and media files, it can describe far more than the structure of a
website. It can help us learn new things beyond the knowledge we explicitly programmed into our application. It’s connections make statements. And statements, together, tell stories.
A link in Linked Data is, in fact, often referred to as a statement. It has the power, in and of itself, to make an
assertion – to state a fact. It does so in very much the same way we humans do when we make a statement about something. We connect a subject to an object by way of some predicate.

This is the basic sentence structure we learned in grade school, remember? The subject of a sentence is the person, place, or thing that is performing the action. The predicate expresses the action or being. And the object indicates to whom or for whom the action is being done; it receives the action.
As simple as this statement is, a hyperlink would not commonly express the same underlying meaning. A blog post written by Jack might anchor to a blog post written by Jill, but that hyperlink relates the two documents, not the two people. It doesn’t say that Jill is a friend of Jack or Jack a friend of Jill.
A link in Linked Data is an RDF statement, which also has a subject, predicate, and an object.

The subject is a URI, which could resolve to some representation of a resource. What differentiates this from
traditional linking on the Web is that the subject is assumed to represent any kind of thing, document or
real-world. The URI is used more like an identifier than a locator. That’s why we use the term URI instead of URL. It’s kind of like a primary key for a record in a database, if you know how that works. Only this time, the
database is your entire corporate intranet or the World Wide Web.
The predicate, the part that does the actual linking, is a property, which expresses the nature of the relationship. Though that property is also expressed with a URI, its URI represents some relational concept such as friend of, has sibling, or has mother. Such predicates (or properties) are often borrowed from well-established public vocabularies and as such, they express semantics or meaning that computers can be programmed to understand.
The object, the part that is linked to, is either some literal value (like a date, integer, string) or it is another
resource with its own URI – some other real-world thing with a representation on the Web. And here’s the kicker. This object can be the subject of its own statements, with entirely new properties linking to entirely new objects. And that kind of linking creates a graph that has the power to grow far beyond what you and your single app can ever know alone. That’s power.
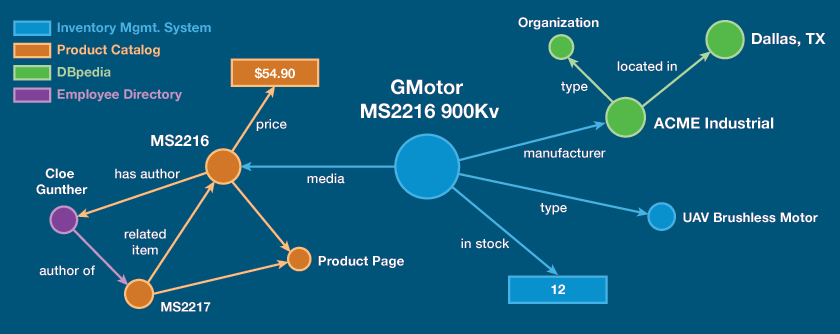
You can imagine the possibilities on a global scale, can’t you? Think about how far the traditional HTML hyperlink has gotten us. They’ve been the glue for what today we call the World Wide Web. But if they can do all that, just imagine what the RDF triple, the link in Linked Data, can do.
Want to know more?
Now that you understand the basic idea behind Linked Data and why it can make your applications more powerful, you can learn more from the following related resources.
![]()
LEARN ABOUT THE RESOURCE DESCRIPTION FRAMEWORK FROM THE W3C’S RDF 1.1 PRIMER.