
Recently, we released Carbon LDP™ version 5. New support for enterprise-class databases and clustering, among other features, make this our most significant release to date. At this milestone, I thought I would share the story of how and why we created the platform. Many may be unaware that we’ve spent the last five years in research and development and that the concept was born eight years before that. It’s something I’ve been involved with for thirteen years now and it’s part of the reason why I left IBM to help establish our company, Base22.
Originally, I didn’t set out to build a Semantic Web system. It was a year before the term Linked Data had been coined by Tim Berners-Lee and nine years before the Linked Data Platform (LDP) became a W3C standard. I just wanted to build something that would improve our software and solve common software development problems. As it turned out, Linked Data was the answer, but it was not the original goal.
Formerly, as an Architect at IBM, I spent a lot of time working late hours, crunching deadlines, designing systems, and writing code. On more occasions than I’m proud to admit, I found myself facing seemingly impossible deadlines. Yet at the same time, I had an unshakeable desire to do quality work. So, I did what proud craftsmen do – I sacrificed; sleep, weekends, family time, and even vacation time. Even when the fragility of our projects had little to do with my own fault, failure was never an option for me. I plowed hard and, one gig after another, always got the work done.
Along the way, I started thinking about the software development process and how it might be improved. To me, creating new applications seemed harder than it needed to be. I grew increasingly frustrated with all the back-end plumbing that had to be done before work could be completed on the front-end. For a data-centric application, for example, it was not uncommon to work for two weeks or more setting up the database, the model objects, the service tier, SQL queries, and the like.
Having done it over and over again for one app after another, I started wondering why it couldn’t be more dynamic. After all, the data model behind all systems is based on just a few key principles that are always the same. There are domain objects (classes in Java and entities or tables in a database). Each has properties (fields, getters, and setters in Java and columns in a database). And then there are relationships that hold among them (an object oriented model in Java and relational keys in the database with SQL queries to join). The amount of time that it takes to set all of that up is just one part of the problem.
Another problem is that once you’ve designed the database schema, everything else becomes quite rigidly tied to it. Business stakeholders expect that changes such as the addition of a single data attribute should be simple. Making such a change should be as simple as it sounds, but seemingly “simple” changes have enormous downstream side effects. The database schema has to be altered. Java classes need to be modified, recompiled, and redeployed. SQL queries need to be changed. Unit tests modified. Regression tests run. All for the addition of a single attribute? Yep. And that’s not even the whole of it.
Next, you have to think about systems integration. In addition to the layers of change required inside of one application, there may be more across interoperating systems – the complexity of which increases exponentially for each new component in a participating network. A network of three components has only three possible connections.
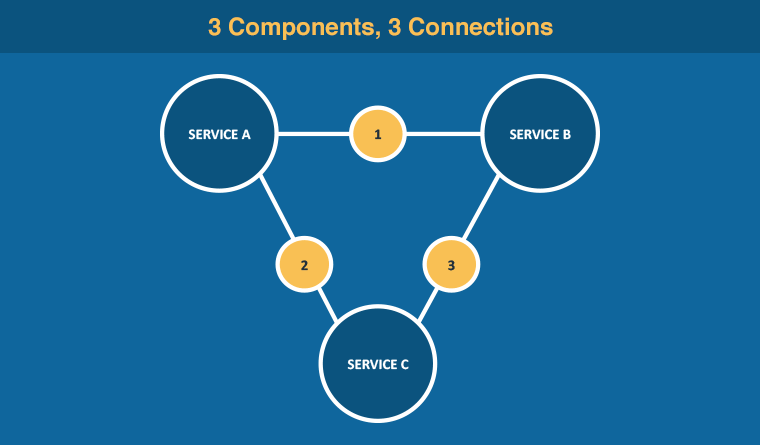
Simply add two more components to such a network and the amount of possible connections increases to ten. It’s no wonder that data silos tend to stay that way – with value trapped within a single system!

If you change your API in such a way that the interface changes, then how many consumers will also need to be changed? And keep in mind, this was all thirteen years ago – before the big data explosion, before cloud computing became the norm, before micro-services were a thing. Today, solutions are comprised of interoperating systems and services more than ever before. This is the stuff that kept me up at night. So, on one particular night, I posted a question to the community of geeks online. I can’t remember the exact words, but it was something like this…
“Why do we have to make an application-specific database and object model every time? Isn’t there a way to make that part dynamic so that instead of hard-coding, compiling, and deploying, we could just … I don’t know… change a config file?”
In other words, how can we define the data model more dynamically, and have all the plumbing for creating, reading, updating, and deleting the data be more immediately available? If there was a way, I wanted to find it. If it didn’t exist, I wanted to invent it. And thus began the vision for what would eventually become Carbon LDP.
I got several replies about the complexity of the problem. About various poor attempts to solve it in the history of the industry. The performance problems that arise when you try to make a database schema for making dynamic database schemas. But one mysterious reply, in particular, piqued my interest. Someone said, simply, “You should check out RDF.”
I Googled “RDF” to find that it was an acronym for the Resource Description Framework – a W3C standard model for data interchange on the Web. I learned that RDF has features that facilitate data merging even if the underlying schemas differ, and that it specifically supports the evolution of schemas over time without requiring all the data consumers to be changed. I also learned that it was part of a family of technologies and concepts that make up this thing called the Semantic Web. I had to Google that too.
As it turns out, the Web as we know it is quite far from reaching its full potential. It’s a Web of documents primarily made for humans to read. It’s difficult for computers to understand that information or interoperate with one another because the information is only semi-structured. It lacks the semantics or meaning that computers can use. The Semantic Web was a vision for introducing semantics into the existing architecture of the web so that webs of documents can become webs of data. Instead of one big giant library of web pages, for example, imagine the web as one big database. That was the general idea.
But it was, at the time, a very academic concept – the purview of A.I. enthusiasts and PhDs. And this was before A.I. was mainstream; before Watson beat the Jeopardy champion and back when most people still believed that A.I. was a pipe dream. It was so academic and confusing that I probably spent three years in study before the lightbulb went on.
The lightbulb moment happened for me when I realized that the RDF graph model presented a viable solution to the problem of making data systems more dynamic. Why? Because there’s no inherent structure in an RDF graph database. There are no rigid schemas to be defined. Structure emerges from the data itself, so structural changes can be made by simply changing the data. A properly designed system can function dynamically against these changes with a reduced need for rewriting code. This is immensely powerful, but deceptively simple. In a nutshell, here’s how it works.
An RDF graph is just a collection of simple, three-part statements called “triples”. The statements have a subject, predicate, and object kind of like the sentence structure we learned in grade school.
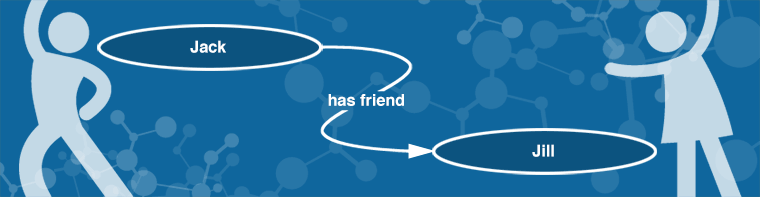
RDF leverages web URIs to identify things, so technically, that same statement would really look something more like this:

Here, we can see why we use the term, Linked Data. That statement creates a link between the resource, Jack, and the resource Jill by way of the property hasFriend. It’s similar to a hyperlink, but more powerful because the nature of the relationship is semantically described. Instead of an arbitrary link between one resource and another (as is the case with traditional hyperlinks), this link has meaning. A traditional hyperlink from Jack’s blog to Jill’s blog, for example, would say nothing about the nature of the relationship. But this link identifies Jack and Jill as people, and the relationship as a friendship. So, it is infused with meaning (semantics) and we’re referring to data entities, not just web pages.
Now, suppose that we want to add a new data property. In a traditional relational database, we’d have to add a new column to the database schema. We’d probably have to rewrite some SQL queries. We’d probably also have to add the new property in software code (both on the server-side and on the front-end). Since an RDF graph is just a list of three-part statements, however, all we need to do is add a new one to the list. Without any changes to schema, we can give Jack a new property, such as an email address, just by inserting another triple like this…
<http://example.com/people#jack><http://example.com/person#hasEmail> "jack@example.com"
We can invent new properties on the fly and shove them in the database against the appropriate subjects, like Jack or Jill, with either literal values (e.g. a strings, dates, numbers) or with a value that’s another URI (a link to another data entity). You don’t have to create a rigid schema. You don’t have to define any new tables or columns or primary / foreign key relationships. In fact, you can think of an RDF database as just one single table with three columns for subject, predicate, and object. When we want to change the data or the structure of the data, we just insert new statements.
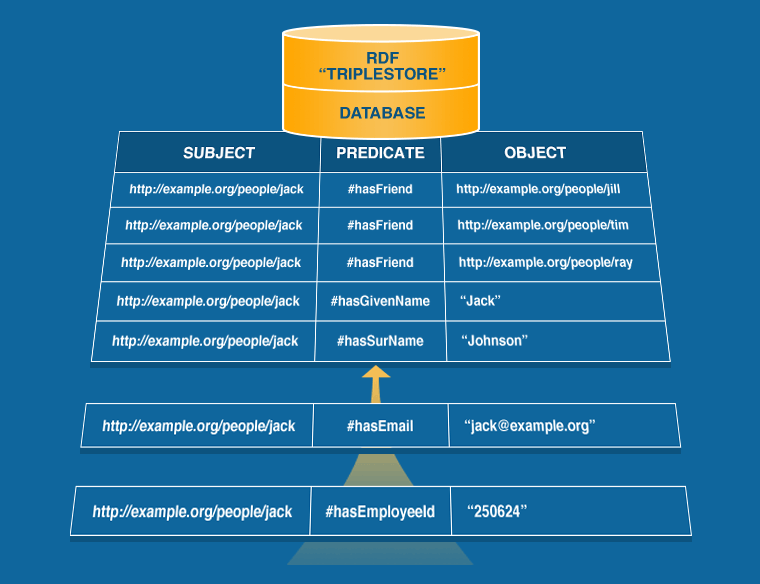
Structure emerges dynamically from the properties we define, which are themselves data (not schema), and from the links that are made between resources. The subjects, objects, and literal values are nodes in a graph and the properties are the links between them. In this way, we can see how a complex graph of relationships can emerge from a simple stack of triples in the database. The graph can exist in one database or it can span across several.
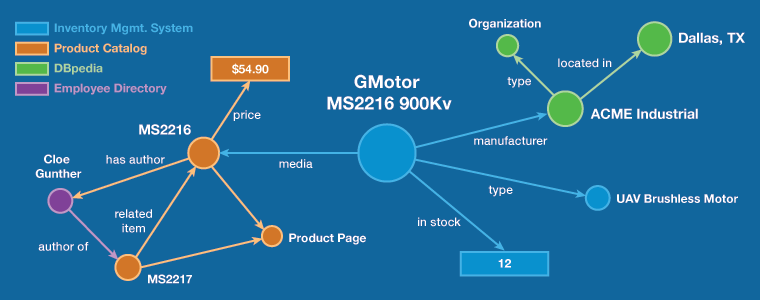
Indeed, the entire universe can be described by simple three-part statements in a single, schema-less table (the RDF database or triplestore). This schema-less flexibility means that we don’t have to know all the requirements for our data up front. We can build an app and let the data evolve as we go. We can write application logic to understand the meaning of the specific properties we invent or we can code the app to respond to those properties generically (based on data types). In other words, we can make rapid changes to an application just by changing the data. Since the basic structure of RDF itself doesn’t change (it’s always just a list of three-part statements), we rarely have to change how our code reads those statements.
While I’ve explained this at a very high level, it’s turns out to be a viable solution for rapid application development, evolution, and integration. So, whoever it was that replied to my question so many years ago was right. RDF would be key to building data-centric systems in a much more rapid and dynamic way. And so, we settled on it as the data model that Carbon LDP™ would use. It just so happens that this design choice makes Carbon LDP applications inherently Semantic Web applications, or Linked Data solutions, but that’s just a wonderful side effect; it wasn’t the original goal.
The goal has always been simple:
- to make is faster and easier to build applications,
- to make it easier to modify them over time, and
- to make it easier to integrate (link) them to increase value.
With its foundation in Semantic Web and Linked Data technologies like RDF, Carbon LDP™ has evolved into a robust platform that achieves these goals. Still, developers needn’t be experts in these concepts. Having gone through the pain of the learning curve ourselves, we’ve been adamant that Carbon LDP should abstract those concepts away from concern. Now, Carbon LDP™ is a platform for creating, evolving, and integrating applications faster and easier than ever before and in ways that are accessible to the everyday developer.
As developers who have struggled with ever-changing requirements and seemingly impossible deadlines, Carbon LDP™ has been the platform we’ve always wanted. So, we built it. Now we can build apps faster, change them more readily, and integrate them wisely. In short, we can now build smarter solutions, and so can you.
Carbon LDP™ v5 is now available in two license tiers: Standard and Enterprise. The Standard edition is still free and has all features using a local file system database. The Enterprise edition features support for enterprise-class databases like Stardog and GraphDB™ for building apps that scale. You don’t have to go through years of study to understand Linked Data; we’ve done that for you and it’s all under the hood. With Carbon LDP, you can build robust, data-centric web apps using mostly front-end code and with a reduced need for server-side plumbing. With all that painful plumbing out of the way, you can build apps faster and focus on the parts that really matter, like the user experience.
I’m very proud of how far we’ve come with Carbon LDP™ and I think you’ll understand why if you simply try it for yourself. See our Quick start guide to learn how to run the free Standard edition or learn more at carbonldp.com. It has taken a long time to realize a vision that began almost thirteen-years ago, but the results speak for themselves. I’ve always said that things of lasting quality and value take time. Now that we’ve put in that time, we are finally reaping the benefits and we hope you will too.